

【導(dǎo)讀】減少邊緣節(jié)點(diǎn)的洞察時(shí)間可在獲得數(shù)據(jù)之后盡快做出關(guān)鍵決定。然而,理論上處理能力和通信數(shù)據(jù)均不受限制,則可將所有全帶寬邊緣節(jié)點(diǎn)檢測(cè)信息發(fā)送至遠(yuǎn)端的云計(jì)算服務(wù)器。此外,還可以進(jìn)行大量運(yùn)算,以挖掘做出明智決策所需的寶貴細(xì)節(jié)信息。所以,電池電量、通信帶寬和計(jì)算周期密集型算法的局限使得我們的設(shè)想只是一種概念,而無法成為實(shí)際方案……
邊緣節(jié)點(diǎn)所需的數(shù)據(jù)集可能只是一個(gè)離散的完整寬帶信息子集。同樣,數(shù)據(jù)可以根據(jù)要求進(jìn)行傳輸。高效的超低功耗(ULP)處理也是實(shí)施任何邊緣節(jié)點(diǎn)方案的一個(gè)關(guān)鍵。
智能分區(qū)模式轉(zhuǎn)變
工業(yè)物聯(lián)網(wǎng)及其前身(機(jī)對(duì)機(jī)(M2M)通信)的先鋒時(shí)代在很大程度上是由云平臺(tái)這一主要應(yīng)用推動(dòng)因素的作用定義的。智能系統(tǒng)的洞察力以往都只是依賴于云級(jí)能力。實(shí)際的邊緣傳感器裝置一直以來都相對(duì)簡(jiǎn)單。然而,由于邊緣節(jié)點(diǎn)的低功耗計(jì)算能力比云計(jì)算能力的發(fā)展更迅速,這個(gè)前提目前正在動(dòng)搖。邊緣節(jié)點(diǎn)如今具有檢測(cè)、測(cè)量、解讀和連接數(shù)據(jù)的能力。
智能分區(qū)模式正從連接傳感器模型向智能設(shè)備模型轉(zhuǎn)變,從而提供更多的可用架構(gòu)選項(xiàng),并允許組織部署工業(yè)物聯(lián)網(wǎng),以獨(dú)特的方式改進(jìn)其實(shí)體資產(chǎn)和流程。邊緣計(jì)算分析(亦稱為智能邊緣或解讀)推動(dòng)著這一轉(zhuǎn)變。大規(guī)模的工業(yè)物聯(lián)網(wǎng)部署依賴于一系列安全、高效節(jié)能并且易于管理的多樣化智能節(jié)點(diǎn)。
邊緣分析
最優(yōu)質(zhì)的傳感數(shù)據(jù)仍可邊緣化,且無需細(xì)心留意邊緣節(jié)點(diǎn)分析中應(yīng)用的要求。邊緣傳感器裝置可能會(huì)受到能源、帶寬或原始計(jì)算能力的約束。這些約束條件將影響到能夠?qū)P堆棧刪減為最小閃存或RAM的協(xié)議選擇。這使得編寫程序充滿挑戰(zhàn)性,并且可能需要犧牲一些IP性能。
然而,這要求提前了解清楚需要獲得哪些有價(jià)值的具體信息,才能從檢測(cè)和測(cè)量數(shù)據(jù)中得到預(yù)期結(jié)果。此外,由于空間隔離或應(yīng)用差異,也可能因邊緣節(jié)點(diǎn)的不同而不同。事件報(bào)警、觸發(fā)信號(hào)和中斷檢測(cè)可以忽略大部分?jǐn)?shù)據(jù),只傳輸需要的數(shù)據(jù)。
時(shí)間折舊
貨幣的時(shí)間價(jià)值是一種概念,即現(xiàn)在的一美元比未來某一時(shí)候的一美元更有價(jià)值。類似地,數(shù)據(jù)也存在時(shí)間常數(shù)。數(shù)據(jù)的時(shí)間價(jià)值是指在這個(gè)幾分之一秒檢測(cè)到的數(shù)據(jù)與從現(xiàn)在起一周、一天或甚至一個(gè)小時(shí)之后檢測(cè)到的數(shù)據(jù)不同。此類任務(wù)關(guān)鍵型物聯(lián)網(wǎng)范例有熱沖擊檢測(cè)、氣體泄漏檢測(cè)或需要采取立即行動(dòng)的災(zāi)難性機(jī)械故障檢測(cè)。時(shí)間敏感型數(shù)據(jù)價(jià)值在解讀之時(shí)開始衰減。有效解讀數(shù)據(jù)和采取行動(dòng)的延遲越長,決策的價(jià)值將越低。為了解決工業(yè)物聯(lián)網(wǎng)的時(shí)間折舊問題,我們必須進(jìn)一步深入了解信號(hào)鏈。
邊緣傳感器節(jié)點(diǎn)的處理算法可對(duì)抽樣數(shù)據(jù)進(jìn)行篩選、抽取、調(diào)諧和精處理,將其分解至最低要求的子集。這首先需要定義目標(biāo)窄帶數(shù)據(jù)??烧{(diào)帶寬、抽樣率和動(dòng)態(tài)范圍有助于一開始就在硬件的模擬域中建立基準(zhǔn)。通過使用所需的模擬設(shè)置,傳感器只會(huì)檢測(cè)需要的信息,并提供更短的時(shí)間常數(shù)以獲得高質(zhì)量的解讀數(shù)據(jù)。
邊緣處的數(shù)字后端處理濾波器可進(jìn)一步重點(diǎn)關(guān)注目標(biāo)數(shù)據(jù)。邊緣傳感器處的數(shù)據(jù)頻率分析可在信息離開節(jié)點(diǎn)之前,并及早判定信號(hào)內(nèi)容。一些高階計(jì)算模塊執(zhí)行快速傅里葉變換(FFT)、有限脈沖響應(yīng)(FIR)濾波并使用智能抽取,可縮小抽樣數(shù)據(jù)的范圍。在一些情況下,在大幅度降低數(shù)據(jù)帶寬之后,只需要從邊緣傳感器節(jié)點(diǎn)處傳輸通過或未通過信息增量痕跡。
圖1中,我們可以看到在未使用前端模擬濾波器或數(shù)字后端處理濾波器的情況下,抽取8次(左側(cè))的簡(jiǎn)單信號(hào)將混疊新的干擾信號(hào)(中間),從而使頻率折疊成期望的新信號(hào)頻帶(右側(cè))。數(shù)字后端處理濾波器搭配數(shù)字信號(hào)處理器(DSP)或微控制器(MCU),同時(shí)將半帶FIR低通濾波器與抽取濾波器一起使用,將能夠?yàn)V除混疊的干擾信號(hào),從而有助于防止出現(xiàn)這一問題。
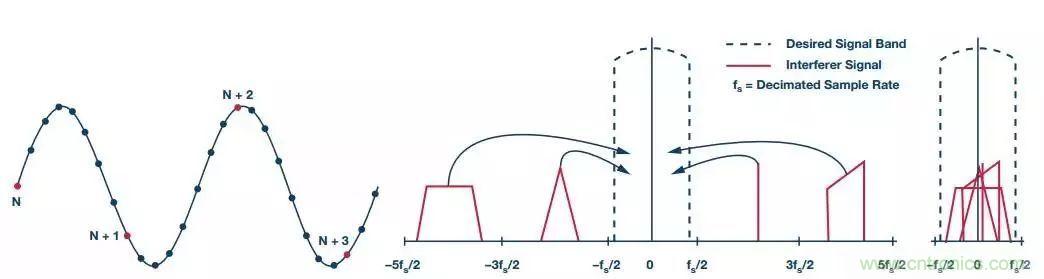
圖1. 在未使用前端濾波器或數(shù)字后端處理濾波器的情況下,可能會(huì)出現(xiàn)混疊
邊緣節(jié)點(diǎn)處理洞察力—智能工廠
領(lǐng)先的工業(yè)物聯(lián)網(wǎng)應(yīng)用解決方案適用于工廠機(jī)器狀態(tài)監(jiān)控。該解決方案的目的是在發(fā)生故障之前識(shí)別和預(yù)測(cè)機(jī)器性能問題。邊緣傳感器節(jié)點(diǎn)的多軸高動(dòng)態(tài)范圍加速度計(jì)用于監(jiān)控工業(yè)機(jī)器上不同部位的振動(dòng)位移。可以篩選和抽取原始數(shù)據(jù),在微控制器中進(jìn)行頻域解讀??梢蕴幚砼c已知性能極限進(jìn)行比較的FFT,針對(duì)下游的通過、未通過和警示警報(bào)進(jìn)行測(cè)試。通過FIR濾波去除目標(biāo)帶寬外的寬帶噪聲,可實(shí)現(xiàn)FFT內(nèi)的處理增益。
邊緣節(jié)點(diǎn)處理是機(jī)器狀態(tài)監(jiān)控的一個(gè)重要組成部分。抽樣數(shù)據(jù)的全帶寬是實(shí)現(xiàn)無線網(wǎng)關(guān)聚集的一個(gè)重要瓶頸。要考慮到,一臺(tái)機(jī)器可能配有許多傳感器,并且可能同時(shí)監(jiān)控?cái)?shù)百臺(tái)機(jī)器。微控制器中作出的濾波和智能決策向無線收發(fā)器提供一個(gè)低增益帶寬輸出,而無需在云端進(jìn)行密集型濾波處理。
圖2顯示了一個(gè)機(jī)器狀態(tài)監(jiān)控的信號(hào)鏈,在這個(gè)信號(hào)鏈中加速度計(jì)傳感器用于測(cè)量位移振動(dòng)特征。利用邊緣傳感器節(jié)點(diǎn)處的后端處理濾波器,可通過在濾波和抽樣數(shù)據(jù)后進(jìn)行FFT運(yùn)算,從而在目標(biāo)窄帶寬中完成頻率分析。

圖2. 振動(dòng)監(jiān)控的典型信號(hào)鏈
在FFT計(jì)算過程中,與實(shí)時(shí)示波器一樣,處理濾波器可無視時(shí)域活動(dòng),直至完成FFT。第二個(gè)線程中的另一種時(shí)域路徑可能還可用于防止出現(xiàn)數(shù)據(jù)分析差異。
如果能夠清楚目標(biāo)機(jī)械特征頻率,則可設(shè)計(jì)微控制器中的ADC和FFT抽樣率,使最大能量適合單個(gè)直方圖倉的寬度。這將防止信號(hào)功率泄漏到多個(gè)倉中,從而降低幅度測(cè)量的精度。
圖3為FFT的一個(gè)示例。在這個(gè)示例中,我們?cè)谶吘壒?jié)點(diǎn)MCU中對(duì)不只一個(gè)觀察的機(jī)械零件進(jìn)行特定的預(yù)定區(qū)解讀。在所需綠色區(qū)域中達(dá)到峰值的能量代表正常運(yùn)轉(zhuǎn),而黃色和紅色區(qū)域則分別表示警報(bào)和嚴(yán)重警報(bào)。更低的數(shù)據(jù)速率警報(bào)或觸發(fā)痕跡可能會(huì)在目標(biāo)區(qū)域內(nèi)向系統(tǒng)發(fā)出偏移事件報(bào)警,而不是傳全帶寬傳感器數(shù)據(jù)。
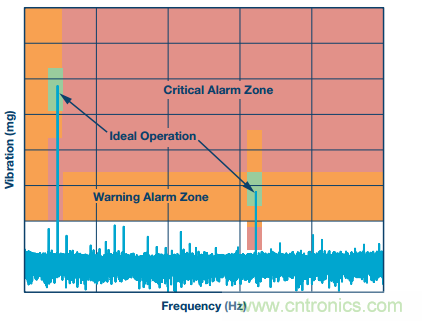
圖3. FFT倉能源可用于觸發(fā)警報(bào)
動(dòng)態(tài)范圍、標(biāo)記和精度
邊緣分析的計(jì)算功率有幾個(gè)選項(xiàng)。許多選項(xiàng)可用于處理算法,從一個(gè)提供有限控制性能的簡(jiǎn)單MCU到更加復(fù)雜的精密片上系統(tǒng)(SoC) MCU,再到到功能強(qiáng)大的多核數(shù)字信號(hào)處理。處理內(nèi)核尺寸、單核或雙核操作、指令RAM緩存大小和定點(diǎn)與浮點(diǎn)需求都是典型的技術(shù)考慮。通常,需要在節(jié)點(diǎn)可用的功率預(yù)估和應(yīng)用的計(jì)算需求之間作出權(quán)衡。
針對(duì)數(shù)字信號(hào)處理,采用定點(diǎn)和浮點(diǎn)兩種格式來存儲(chǔ)和操作以數(shù)字表示的傳感器節(jié)點(diǎn)數(shù)據(jù)。定點(diǎn)是指一種數(shù)字表示方式,采用小數(shù)點(diǎn)后(有時(shí)候?yàn)樾?shù)點(diǎn)前)固定位數(shù)的數(shù)字表示。使用這種方法的DSP處理整數(shù),例如使用最少16位的正負(fù)整數(shù),可能有216種位模式。相比之下,浮點(diǎn)則使用有理數(shù),最少可能有232種模式。與使用定點(diǎn)的DSP相比,使用浮點(diǎn)計(jì)算方法的DSP可處理更大范圍的值,并能夠表示非常大或非常小的數(shù)字。
浮點(diǎn)處理可確保能夠表示更大動(dòng)態(tài)范圍的數(shù)字。如果需要計(jì)算大量傳感器節(jié)點(diǎn)數(shù)據(jù),并且在檢測(cè)之前可能并不清楚確切的范圍,則浮點(diǎn)處理就非常重要。此外,由于每一個(gè)新的計(jì)算都需要進(jìn)行一次數(shù)學(xué)運(yùn)算,所以計(jì)算結(jié)果必然會(huì)出現(xiàn)四舍五入或截?cái)嗟默F(xiàn)象。這會(huì)導(dǎo)致數(shù)據(jù)出現(xiàn)量化誤差或數(shù)字信號(hào)噪聲。量化誤差是理想的模擬值與該值的數(shù)字表示(即最接近的舍入值)之差。這些值之間的量化差越大,數(shù)字噪聲將越明顯。當(dāng)準(zhǔn)確性和精度對(duì)于解讀的傳感器數(shù)據(jù)來說非常重要時(shí),浮點(diǎn)處理則可實(shí)現(xiàn)優(yōu)于定點(diǎn)處理的精度性能。
性能
固件設(shè)計(jì)師應(yīng)以最有效的方式實(shí)現(xiàn)計(jì)算應(yīng)用,因?yàn)閳?zhí)行操作的速度至關(guān)重要。因此,必須描述數(shù)據(jù)解讀的處理需求,以便確定實(shí)現(xiàn)最大效率需要使用定點(diǎn)計(jì)算還是浮點(diǎn)計(jì)算。
我們可以對(duì)定點(diǎn)處理器進(jìn)行編程,使其能夠執(zhí)行浮點(diǎn)任務(wù),反之亦然。然而,這樣做的話效率非常低,并將影響處理器性能和功率。當(dāng)針對(duì)無需密集型計(jì)算算法的高容量通用應(yīng)用而優(yōu)化時(shí),定點(diǎn)處理器的表現(xiàn)更加突出。相反,浮點(diǎn)處理器可利用專門的算法,輕松完成開發(fā),并實(shí)現(xiàn)更高的整體精度。
雖然性能不是很高,但是處理器中支持的GPIO引腳數(shù)量則可作為第二個(gè)選擇標(biāo)準(zhǔn)。直接支持目標(biāo)傳感器(例如:I2C、SPORT和UART)的相應(yīng)控制界面可降低系統(tǒng)設(shè)計(jì)的復(fù)雜程度。內(nèi)核處理時(shí)鐘速度、每次執(zhí)行的位數(shù)、可用于處理的嵌入式指令RAM數(shù)量以及存儲(chǔ)器接口速度都將影響邊緣節(jié)點(diǎn)處理的能力。實(shí)時(shí)時(shí)鐘有助于對(duì)數(shù)據(jù)進(jìn)行時(shí)間標(biāo)記,并允許調(diào)整多個(gè)平臺(tái)之間的處理。
處理計(jì)算能力通常是在MIPS或MMAC中定義。MIPS是一秒鐘內(nèi)可執(zhí)行的百萬指令數(shù)。MMAC是每秒可執(zhí)行的32位單精度浮點(diǎn)或定點(diǎn)累加乘法操作次數(shù)(單位:百萬)。針對(duì)16位和8位操作,MMAC性能值分別提高2倍和4倍。
安全
雖然工業(yè)物聯(lián)網(wǎng)的安全影響著每個(gè)系統(tǒng)、每次傳輸和每個(gè)數(shù)據(jù)接入點(diǎn),但是微控制器和DSP則提供內(nèi)部安全特性。高級(jí)加密標(biāo)準(zhǔn)(AES)提供了一種增強(qiáng)有線通信線路(如UART/SPI)或無線通信線路安全性的方法。在采用無線RF通信的情況下,通過邊緣節(jié)點(diǎn)無線電進(jìn)行有效傳輸之前會(huì)先執(zhí)行AES加密。接收節(jié)點(diǎn)相應(yīng)地執(zhí)行解密操作。電子密碼模塊(ECB)或密碼塊鏈接 (CBC)是典型的AES模式。通常,128位或更長位數(shù)的安全密鑰是首選。真隨機(jī)數(shù)發(fā)生器用作為處理器中安全計(jì)算的組成部分。后續(xù)的工業(yè)物聯(lián)網(wǎng)文章中將進(jìn)一步描述這些方案的細(xì)節(jié),以便大家采用更加全面的安全措施。
單核或雙核
對(duì)原始數(shù)據(jù)處理能力的需求終始很旺盛。高效的原始數(shù)據(jù)處理能力將更勝一籌。多核MCU和DSP可為特別受益于密集型并行處理的算法提供額外的計(jì)算能力。然而,處理異構(gòu)數(shù)據(jù)的需求也在不斷上升。這導(dǎo)致一類多核微控制器的問世,此類微控制器將兩個(gè)或更多具有不同特定功能優(yōu)勢(shì)的內(nèi)核整合在一起。一般稱為異構(gòu)或非對(duì)稱多核設(shè)備,通常整合了兩個(gè)配置完全不同的內(nèi)核。
非對(duì)稱MCU可整合ARM®Cortex®-M3和Cortex-M0,使用處理器間通信協(xié)議進(jìn)行通信。這使M3能夠重點(diǎn)處理繁瑣的數(shù)字信號(hào)處理任務(wù),而M0則執(zhí)行密集程度較低的應(yīng)用控制。這樣可以將更簡(jiǎn)單的任務(wù)分流至小型內(nèi)核中處理。分區(qū)可最大化功能更強(qiáng)大的M3內(nèi)核的處理帶寬,以便進(jìn)行計(jì)算密集型處理,而這是協(xié)同處理的真正核心所在。核間通信采用共享SRAM,其中一個(gè)處理器引發(fā)中斷,而另一個(gè)檢查。當(dāng)接收處理器在響應(yīng)時(shí)引發(fā)中斷,就會(huì)發(fā)出報(bào)警。
異構(gòu)多核MCU的另一個(gè)優(yōu)勢(shì)在于,它可以克服嵌入式閃存的限速問題。通過在兩個(gè)小型內(nèi)核中以非對(duì)稱的方式對(duì)任務(wù)進(jìn)行分割,可在實(shí)現(xiàn)內(nèi)核的全部性能的同時(shí),仍繼續(xù)使用低成本嵌入式存儲(chǔ)器。實(shí)現(xiàn)嵌入式閃存的成本通常決定MCU的成本,因此可有效地消除瓶頸。在可用的功率預(yù)算中平衡處理器需求是工業(yè)物聯(lián)網(wǎng)邊緣傳感器節(jié)點(diǎn)設(shè)計(jì)的關(guān)鍵部分。
功率平衡
即使是在可以實(shí)現(xiàn)能量采集的情況下,許多工業(yè)物聯(lián)網(wǎng)邊緣傳感器節(jié)點(diǎn)也必須能夠在同一小型電池上運(yùn)行多年。ULP操作將是這些節(jié)點(diǎn)的一個(gè)關(guān)鍵參數(shù),而且必須選用能夠最小化節(jié)點(diǎn)實(shí)際功耗的元件。
許多非常適用于工業(yè)物聯(lián)網(wǎng)的MCU都采用ARM系列的Cortex-M嵌入式處理器,針對(duì)低功耗MCU和傳感器應(yīng)用。包括針對(duì)更簡(jiǎn)單高效應(yīng)用而優(yōu)化的Cortex-M0+,以及需要浮點(diǎn)和DSP操作的高性能復(fù)雜應(yīng)用的Cortex-M4。使用性能更高的處理內(nèi)核可能會(huì)影響低功耗性能。
ARM CPU在代碼大小、性能和效率方面提供了一個(gè)新方向。但是對(duì)于MCU在工作模式或深度睡眠模式下的實(shí)際功耗,許多超低功耗能力完全取決于MCU供應(yīng)商。工作功耗深受工藝技術(shù)選擇、超高速緩存和處理器整體架構(gòu)的影響。MCU睡眠電流以及CPU處于睡眠模式時(shí)的可用外圍功能主要受MCU的設(shè)計(jì)和架構(gòu)影響。
行業(yè)聯(lián)盟EEMBC制定了一些衡量基準(zhǔn),幫助系統(tǒng)設(shè)計(jì)師了解其系統(tǒng)的性能和能量特性,以選擇最優(yōu)處理器。每個(gè)器件的ULPMark™- CP評(píng)分是經(jīng)過計(jì)算得出的單個(gè)數(shù)字品質(zhì)因素。該套件中每個(gè)衡量基準(zhǔn)的評(píng)分使設(shè)計(jì)師權(quán)衡并合計(jì)這些衡量基準(zhǔn),以滿足特定的應(yīng)用需求。
傳感器邊緣節(jié)點(diǎn)的功率預(yù)算將直接與其處理能力相互關(guān)聯(lián)。如果功率預(yù)算無法滿足邊緣節(jié)點(diǎn)分析的處理需求,則可能需要作出權(quán)衡。性能效率會(huì)影響傳感器邊緣節(jié)點(diǎn)的電源效率。微控制器的典型能耗指標(biāo)用于指定每兆赫茲計(jì)算消耗的有功電流量。例如:針對(duì)基于ARM Cortex-M3的MCU,功耗可達(dá)到數(shù)十μA/MHz。
占空比
邊緣傳感器節(jié)點(diǎn)的功耗最小化通?;趦蓚€(gè)因素:節(jié)點(diǎn)在活動(dòng)狀態(tài)下的功耗是多少;以及為進(jìn)行檢測(cè)、測(cè)量和解讀,節(jié)點(diǎn)必須保持活動(dòng)狀態(tài)的頻率如何。這個(gè)占空比將隨著節(jié)點(diǎn)中使用的傳感器和處理器類型,以及算法需求的不同而變化。
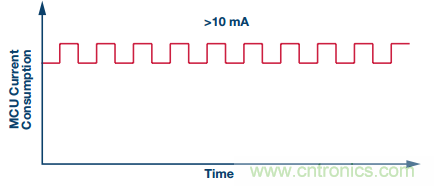
圖4. 邊緣傳感器節(jié)點(diǎn)MCU的主要活動(dòng)狀態(tài)可能會(huì)消耗過多的功率
在不考慮MCU功耗的情況下,邊緣傳感器節(jié)點(diǎn)的主要活動(dòng)狀態(tài)將消耗大量功率,并將電池供電應(yīng)用的壽命減少至只有幾個(gè)小時(shí)或幾天。
通過分析節(jié)點(diǎn)內(nèi)部元件的占空比,可節(jié)省大量能源,從而確保只有在必須的情況下這些元件才會(huì)處于工作狀態(tài)。MCU幾乎一直處于常開狀態(tài)。為了使MCU能夠保持對(duì)邊緣傳感器節(jié)點(diǎn)的完全控制,同時(shí)消耗盡可能少的能量,必須采用針對(duì)低能耗操作的特定架構(gòu)。最小化MCU能耗就是要使MCU盡可能經(jīng)常處于睡眠模式,同時(shí)在需要的時(shí)候仍能執(zhí)行關(guān)鍵任務(wù)。
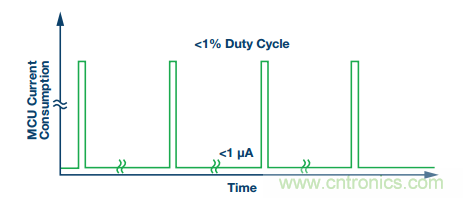
圖5. 將MCU主要保持在非活動(dòng)狀態(tài),以便將功耗降至最小
對(duì)于大多數(shù)非活動(dòng)狀態(tài)、只在短期占用時(shí)間處于活動(dòng)狀態(tài)的情形,使MCU在低功耗休眠模式下運(yùn)行,可將邊緣節(jié)點(diǎn)的電池使用壽命延長至許多年。
可能無需在工業(yè)物聯(lián)網(wǎng)中使用許多邊緣節(jié)點(diǎn)檢測(cè)解決方案就可以處理連續(xù)不間斷的數(shù)據(jù)流。利用中斷事件閾值忽略已知的超范圍條件數(shù)據(jù),這樣可降低處理功率。為了保持功率和帶寬,可能需要提前了解可預(yù)測(cè)的占空比。此外,基于已檢測(cè)信息狀態(tài)的可變占空比可觸發(fā)活動(dòng)狀態(tài)或降低功率狀態(tài)。
微控制器或DSP的響應(yīng)時(shí)間和功耗(開啟和關(guān)閉狀態(tài)下)是低帶寬應(yīng)用的重要設(shè)計(jì)依據(jù)。例如:建筑中,溫度和光傳感器的數(shù)據(jù)傳輸在靜止期間可能明顯減少。這不僅可以延長傳感器節(jié)點(diǎn)的休眠時(shí)間,而且還可以大大減少信息傳輸。
為了實(shí)現(xiàn)快速反應(yīng),許多微控制器除了提供完全活動(dòng)模式,還提供各種低功耗工作模式,例如:睡眠模式、靈活模式、休眠模式和完全關(guān)斷模式。每種模式都將在不需要時(shí)關(guān)斷各種內(nèi)部計(jì)算模塊,通常將電流需求改變幾個(gè)數(shù)量級(jí)。為實(shí)現(xiàn)這一節(jié)能優(yōu)勢(shì),向完全活動(dòng)模式過渡需要最低有限響應(yīng)時(shí)間。采用靈活模式這一混合配置時(shí),計(jì)算內(nèi)核處于睡眠模式,而外圍接口仍處于活動(dòng)狀態(tài)。休眠模式可提供SRAM數(shù)據(jù)存儲(chǔ)功能,并可選擇允許實(shí)時(shí)時(shí)鐘仍保持活動(dòng)狀態(tài)。
圖6為詳細(xì)的MCU功耗與時(shí)序圖,顯示了每種低功耗MCU模式、過渡時(shí)間和占空比的影響。當(dāng)MCU處于非活動(dòng)狀態(tài)時(shí),使用低功耗模式是保持在低功耗傳感器節(jié)點(diǎn)預(yù)算范圍之內(nèi)的關(guān)鍵。
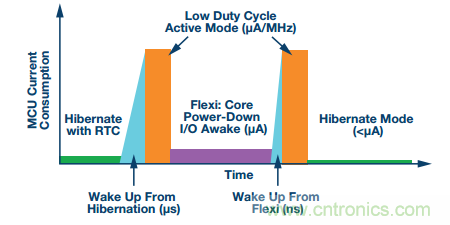
圖6. 詳細(xì)的MCU功耗與時(shí)序圖
傳感器融合
先進(jìn)的模擬微控制器提供了一個(gè)完整的混合信號(hào)計(jì)算解決方案。配備嵌入式精密模數(shù)轉(zhuǎn)換器(ADC)的前端模擬多路復(fù)用器支持更先進(jìn)的傳感器融合技術(shù)。在進(jìn)行數(shù)字處理之前,可將多傳感器輸入發(fā)送至單個(gè)微控制器。片上數(shù)模轉(zhuǎn)換器(DCA)和微控制器反饋至附近其他設(shè)備,可實(shí)現(xiàn)快速反饋回路。其他嵌入式電路模塊(如比較器、帶隙基準(zhǔn)電壓源、溫度傳感器和鎖相環(huán))為多傳感器邊緣節(jié)點(diǎn)提供額外的算法靈活性。
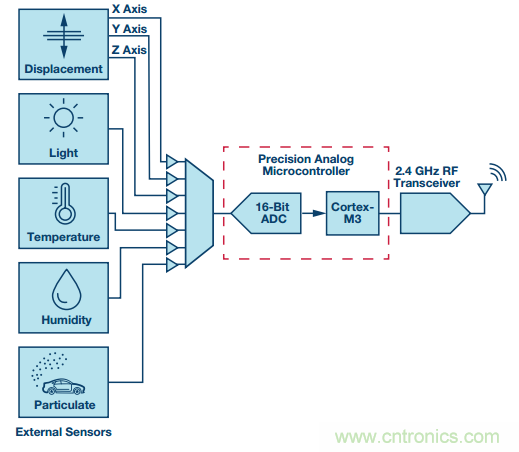
圖7. 可在單個(gè)模擬微控制器中處理多傳感器信號(hào)
多個(gè)傳感器的模擬信號(hào)可發(fā)送至單個(gè)精密模擬微控制器。微控制器中的算法可通過傳感器融合過程實(shí)現(xiàn)信息的智能組合。
室外污染監(jiān)控器應(yīng)用就屬于此類邊緣節(jié)點(diǎn)處理。在此類應(yīng)用中,來自多個(gè)輸入來源(如氣體傳感器、溫度傳感器、濕度傳感器和顆粒傳感器)的數(shù)據(jù)在單個(gè)處理器中融合并進(jìn)行分析。通過這些信息,分析處理完畢后,即可基于只能從本地傳感器節(jié)點(diǎn)那獲知的校準(zhǔn)和補(bǔ)償信息生成污染數(shù)據(jù)。然后,可將這些經(jīng)過校準(zhǔn)的數(shù)據(jù)發(fā)送至云,以便進(jìn)行歷史分析。在一些情況下,可能需要進(jìn)行獨(dú)特的一次性調(diào)試,針對(duì)其特定的環(huán)境失調(diào)配置每個(gè)傳感器節(jié)點(diǎn)。
ADI公司對(duì)ULP平臺(tái)進(jìn)行了大量投資,在傳感器、處理器和節(jié)能模式的強(qiáng)大功能集方面均有重大改進(jìn)。近期發(fā)布的ADuMC3027和ADuMC3029系列微控制器可提供26 MHz ARM Cortex-M3內(nèi)核的性能,同時(shí)在活動(dòng)模式下的工作電流低于38 μA/MHz,而在待機(jī)模式下為750 nA。這種高效的本地處理能力可降低系統(tǒng)的整體功耗,同時(shí)大大減少通過網(wǎng)絡(luò)發(fā)送數(shù)據(jù)進(jìn)行分析的需要。
ADI公司提供各種MCU和DSP引擎,有助于以智能方式捕捉和處理發(fā)送至云的物聯(lián)網(wǎng)數(shù)據(jù)。ADuCM36x系列采用ARM Cortex-M3處理內(nèi)核和集成式雙核∑-? ADC。ADI公司的SHARC® 數(shù)字信號(hào)處理器系列在許多將動(dòng)態(tài)范圍作為關(guān)鍵要素的應(yīng)用中實(shí)現(xiàn)了實(shí)時(shí)浮點(diǎn)處理性能。
新一代Cortex-M33處理器基于ARMv8-M架構(gòu) ,采用可靠的TrustZone™技術(shù),通過處理器的內(nèi)置硬件保證可信應(yīng)用和數(shù)據(jù)的安全。隨著世界的聯(lián)系變得越來越緊密,確保每個(gè)節(jié)點(diǎn)的安全性是促進(jìn)物聯(lián)網(wǎng)應(yīng)用發(fā)展的關(guān)鍵。
本文轉(zhuǎn)載自亞德諾半導(dǎo)體。
推薦閱讀:



